

Unclaimed: Are are working at Hive ?
Hive Reviews: 4.2/5 — Solid Choice
Hive is an all-in-one project management tool developed to “help teams move faster” regardless of how they work. Features are created based on users’ requests and are updated weekly, making Hive the world’s first democratic software platform. It’s best known for its capabilities in project management, time management, team collaboration, automation, and an array of integrations with third-party software. Hive is free to use for solo users and with premium versions available to teams and enterprises.

| Capabilities |
API
|
|---|---|
| Segment |
Small Business
Mid Market
Enterprise
|
| Deployment | Cloud / SaaS / Web-Based, Mobile Android, Mobile iPad, Mobile iPhone |
| Support | 24/7 (Live rep), Chat, Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support |
| Training | Documentation |
| Languages | English |
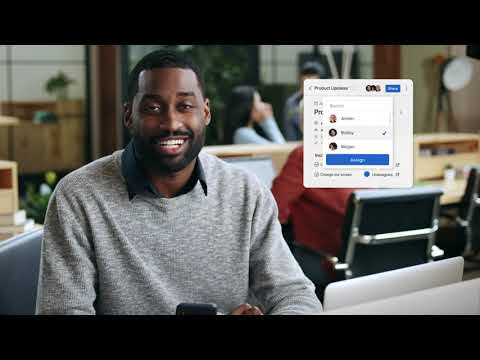

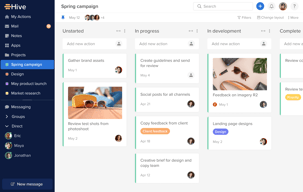
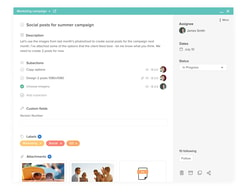






Compare Hive with other popular tools in the same category.
Fantastic and attractive UI Straightforward when it comes to tracking,assigning and monitoring projects Hive helps me keep track of all our projects and people connected to these projects
I don't have anything yet to state as a dislike I am satisfied in using hive
Managing the projects and getting the time logs

Hive is the best Datawarehouse and open source. Easy to use. It has a query language HiveQL. The syntax is same as SQL. So it is easy to write the hive queries and easy to get reports and business insights. Best Olfor analytics. And easily integrated with Spark, Hadoop and cloud also.
Higher latency is the drawback. Developments should be made to improve the latency of the complex queries.
Helping us to get business insights and reporting. Helping us to analyse the data and draw some conclusions to improve the business.

Best thing about Hive is it alows us to write the code in sql for processing and managing the data. It allows us to partition and distribut the data among the cluster machines. We can also choose execution engine like spark, tez,mapredice while rinning in hive. If you your processing and analysing the bulk volume of batch data then hive is best.
It supports only structure data and we can't do updates too. Only supports OLAP.
We are managing our data warehouse for analytical purpose using hive. We used to partition and cluster the tables for better parallel processing and less shuffling so the processing will be optimised. We used to read the hive tables with spark too for better computation and speed.

Good querying on hive databases.and easy to create schemas
It does not allow datatypes conversion. As it will result in lost of data
Querying on hive dbs. Also hs2 and hive metastore resulting fast results
Schema on any format HDFS files. Easy to download the data. A complete tool similar to database tool like toad.
Performance,sometime it is very difficult to run queries. Gui can be improved with more user friendly options
Data processing for regulatory reporting ...maintain lineage
I was a top fan of Impala for a while until I reached a series of limitations that were impossible to overcome. I work a lot with arrays and just the fact of being able to use array_contains in impala made me switch to Hive. Also, we are moving fast on the direction of self made Macross for hive that let us do complex queries without lateral view explodes
Session creation takes a while and speed is quite slow when comparing to Impala
Complex data analysis with tables that have several billion rows by partition
It is highly flexible in configurations. So many options to load data from- directly from linux file system or hdfs. You can create external and managed tables. One fun feature is that you can shoot bash commands from hive as well
It cannot be used for streaming data. Error logging can be improved so that error tracking and resolution can be more efficient.
It is used to transform and process Big Data datasets in batches. It can handle TBs of data. Push predicate feature has greatly improved the performance of the queries and the developer doesn't need to think about it anymore
Hive is great for handling logs in big data projects. We are using the same in our project and it is great for using joins and grouping which is very difficult and tricky in map reduce. It has a lot of udf packages and it is very easy to add new udfs. We were also using bucketing and clustering to optimize the query. Concept of external tables and the way we can manipulate data even when table is deleted from hive is really amazing. Lot of connectors available in the market for different softwares.
The thing which I dislike is latency and the way it saves data. While inserting data I have to wait a lot of few records. Compiler execution plan is very immature as it does not do proper query optimization. Though the community is working fast for overcoming quickly but I think it will take time for hive to be
We are using hive mainly for saving our logs. it helps us to keep track of what records are inserted, which records have failed and what are relationship between them. we are using tableau for analyzing data .
The progression of features, speed, etc brings me the strategic confidence I need in the SQL in hadoop space.
At this point, everything is on pint & theories it is great in hive 1.2
Deriving value from masses of unstructured & structured data.
1) ability to handle PetaByte scale of data 2) ability to work with near SQL query language 3) schema on read capibility
1) optimizer technology is still maturing
1) handling huge datasets 2) handling semi-structured and structured data sets with the same tool


