

Unclaimed: Are are working at Hive ?
Hive Reviews: 4.2/5 — Solid Choice
Hive is an all-in-one project management tool developed to “help teams move faster” regardless of how they work. Features are created based on users’ requests and are updated weekly, making Hive the world’s first democratic software platform. It’s best known for its capabilities in project management, time management, team collaboration, automation, and an array of integrations with third-party software. Hive is free to use for solo users and with premium versions available to teams and enterprises.

| Capabilities |
API
|
|---|---|
| Segment |
Small Business
Mid Market
Enterprise
|
| Deployment | Cloud / SaaS / Web-Based, Mobile Android, Mobile iPad, Mobile iPhone |
| Support | 24/7 (Live rep), Chat, Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support |
| Training | Documentation |
| Languages | English |







Compare Hive with other popular tools in the same category.
The SQL-like syntax makes it easy to use
Its reliance on mapreduce makes it sometimes very slow even for a simple task
Run specific queries on hadoop files
The ability to view HDFS data in a relational format and easily query it through HiveQL
The fact that it uses MapReduce whether you query a pre existing table or a perform a complex query. Tez helps with this issue. Also the inability to delete/update data is a real issue and forces other services to be used eg HBase.
The ability to use Hive on HUE is perfect. We are building a platform for data scientists (prefer GUI to shell) to perform analysis so removing the need for command line is excellent.
It is very simple to use because you fill like you use simple SQL language for querying data. When I just started I didn't have any experience with Hive and in like one week I was able to query big data and do some analysis. In a month I was able to administrate data and create my own databases with the useful data. . .
Not so many implemented functions in the Hive. There are very useful Window functions but it's not enough. . . It's not that simple to modify data inside a table. . .
Analyze every day and every hour or even every minute user experience, user behavior in application or web client , etc . . .
Hive is one of the Apache projects. it is a data warehouse software which facilitates querying and managing large datasets residing in distributed storage. It provides a way to enable easy data extract/transform/load (ETL) Some of the nice features include (1) a simple SQL-like query language, called HiveQL, that enables users familiar with SQL to query the data. But it is a bit different from SQL standard. For example, HiveQL can also be extended with custom scalar functions (UDF's), aggregations (UDAF's), and table functions (UDTF's). (2) You can define your own read or written data format called Hive SerDe. (3) Hive can be run on Hadoop and HDFS. It has very good scalability. Personally speaking, I use hive mainly for ad hoc quires and reports. For BI reports Hive is the best since you can reuse all the SQL that you have done for traditional data warehouses. Also with Hive Server2 you get a real JDBC support so you can plug your BI tools to it. Many more SQL features like cubes, rollups, windowing, lag, lead, etc are being added to Hive through Hortonworks Stinger initiative. Hive also produces very compact code, which is always good for reading and debugging.
Too large code base. It is hard to maintain and support. And, there are too many configurations. If you take a look at the HiveConf.java, you will be confused with so many configurations there. It is easy to get lost when you configure them. And, if you configure some of them in a wrong way, you may suffer from bad query performance.
We are developing Hive. Hive is part of our product
Apache Hive is a tool built on top of Hadoop for analyzing large, unstructured data sets. Most BI and SQL developer tools can connect to Hive as easily as to any other database.
Unable to cancel a running query. Query tuning is difficult compared to RDBMS
We had a requiement to scan a large dataset for our predection algorithm. Initially we used RDBMS but the performace was very slow and user where not happy with it. We replaced RDBMS with the Hive and we are able to see a drastic improvment in the performance.
hiveql is more like SQL and really easy to learn
doesnt work good if you want a low latency queries
performance for 1TB of data
If you know SQL you will be able to get Hive really quickly. Lots of the same functionality but not exactly SQL. Easy to create tables and start writing queries allowing you to dive deeper into your data.
As with all Hadoop tools lots of knobs to tweak. Takes a good bit of time optimize and finely tune your Hive install.
Putting structure on unstructured. Once we chose hive to accomplish the aforementioned task we were able to bring our data to our data scientists quickly. An easier degree of acceptance to the Big Data idea.
Its exhilarating how well it seamlessly connects work, through its group messaging that spurs collaboration, its flexible project layouts, customer insights and reviews that help in strategy.
One thing to note is that its heavy on consumption and it requires enough ram to slow some integrated apps down. That's an issue that needs solving.
Its been using data analysis of the workflows to expose how work is actually being done, what's needed to optimize operations, how to schedule, allocate and much more. Its been a great help at getting everyone performing and moving as per timelines and objectives.
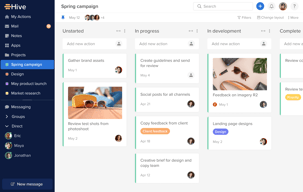
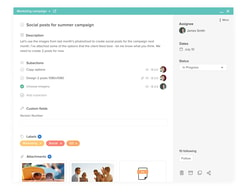
Hive offer tool's for project planning, including the ability for track project and timeline, create and assign tasks and manage resources.
I have no dislike towards hive since is the one I'm using
It allows users to analyse large amount structure and semi structure data
Hive is a very valuable tool as it provides wrappers for data analysis and querying on Big data for organizations with huge amounts of data to be processed. It is built on top of Hadoop and makes SQL query building and storing quite convenient!
The biggest disadvantage of using Hive is that it does not provide or offer real-time queries and especially for row level updates as the latency is quite high in Hive.
Hive solves the problem of big data processing and analysis for me and my company. We are able to process and analyze huge amounts of data with the help of capabilities provided by Hive. It also allows parallel processing which makes it quite fast to use.


