

Unclaimed: Are are working at Hive ?






Hive Reviews: 4.2/5 — Solid Choice
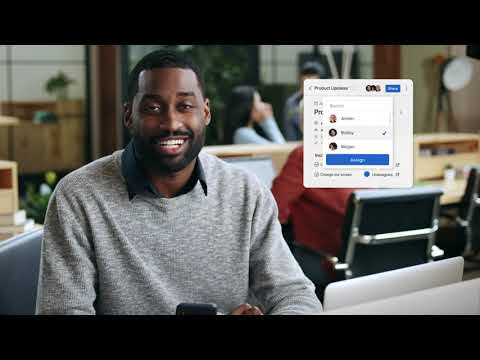
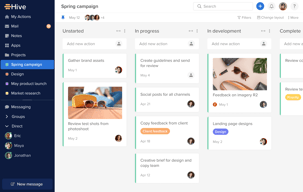
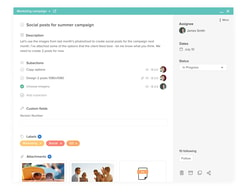
Hive is an all-in-one project management tool developed to “help teams move faster” regardless of how they work. Features are created based on users’ requests and are updated weekly, making Hive the world’s first democratic software platform. It’s best known for its capabilities in project management, time management, team collaboration, automation, and an array of integrations with third-party software. Hive is free to use for solo users and with premium versions available to teams and enterprises.




| Capabilities |
API
|
|---|---|
| Segment |
Small Business
Mid Market
Enterprise
|
| Deployment | Cloud / SaaS / Web-Based, Mobile Android, Mobile iPad, Mobile iPhone |
| Support | 24/7 (Live rep), Chat, Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support |
| Training | Documentation |
| Languages | English |

Compare Hive with other popular tools in the same category.
The best part is being able to use a familiar syntax.
Doesn't support all MYSQL use-cases (understandably).
Ad-hoc queries on ETL'd production data.
To be able to run map reduce jobs using json parsing and generate dynamic partitions in parquet file format.
It is slow compared to Spark/Impala for most operations. Also, it throws Out of Memory if multiple partitions are updated containing many parquet files.
Events are gathered in HDFS by flume and needs to be processed into parquet files for fast querying. The input data contains variable attributes in the json payload as each customer could define custom attributes. It is part of the ETL pipeline, where hive jobs read json data and generates parquet files that would be queried using impala/spark. Using views, each customer queries only the relevant data.
performing SQL-like queries, Partitioning Tables, De-normalizing data, Compress map/reduce output are best benefits
For some cases you cannot do complicated operations using Hive e.g. when output of one job acts as input to the other job (SequenceFileFormat file) or writing query on an image file, Hive is not useful.
Hive helps in resolving big data problems
Hadoop does not have native query language, but Hive is a great addition to use on top of hadoop. I could point to a data stored in hadoop to a specific table and could use normal queries like I usually do in SQL. We can join and do aggregations etc. Makes life pretty simple.
It can be very slow as it runs on map reduce jobs underneath. Data cannot be updated but we will have to do a rewrite.
For people who are used to write SQL queries would have a very good time using Hive on top of hadoop for files stored in HDFS.
-> Easy to configure/create a table for Big data or Streaming data -> Fast and easy to Query. Business/non-technical folks can use HUE for more interactive Querying on Hive tables -> HUE can have saved results and old queries along with exporting results in Excell.CSV
-> Joining and parsing multiple tables with huge sizes still remain a challenge. -> Some of SQL operations doesn't work in hive like non equality joins,
Dumping Site activity Big Data streaming data as well as data logs in Hive
Open source framework allows to read and write and manage tha data like sql , HQl which makes it easy to use.
The latency in Apache hive is very high.
It provides SQL like query language called HQl with schema on read and transparently convert queries to map reduce.
I like the most in Apache Hive supports partitioning and bucketing for fast data retrieval. We can create custom UDF as per the requirements to perform data cleansing and filtering. It supports HQL similar to SQL which gives easy for the people who comes from SQL background.
Doesn't support OLTP and also doesn't support delete or update actions.
We have created a semantic layer in Hive that helps us to process the terabytes of data and generate the reports faster. it also helped us fault tolerance and high availability of the data

Flexible and easy to understand loved it
Not compatible with multiple platforms hence mostly plotform depend
Works best with ETL related works or tasks

It is easy to run query in hive as hive uses hql which is very similar to sql. Hive has hivemetastore service to save the metadata and hiveserver2 to serve the client requests so the segregation here helps in proper resource distribution. Hive is also fault tolerant which makes it ideal to run ETL long running batches
Hive has a problem of cold start and since it used mapreduce algorithm at the backend, it is way slower than spark which made us move to spark from hive as the job completion time after switching to spark got reduced by 70-80%
Informatica data ingestion Abinitio data ingestion and modifications Data formatting (as it provides option such as csv,parauet etc) Data transformation using hive query Data pipelines

The friendliness of the data warehouse tool for the database developers
Not inclusion of acid properties, it doesn't have the acid properties as in the databases
I usually use hive for my big data [data migration problems], the speed at which the query operates, and the option to choose various engines


